

微信检测可批量检测手机号码是否开通微信,国内号码,港澳台号码,国外号码,微信号QQ号等多种号码格式用户批量上传手机号码,平台将快速、自动、批量将手机号中有绑定或者开通微信的号码筛选出来,高速筛选、精准无痕,有效降低运营成本节...
网站首页 > fctime.cn 第22页
-
发布了文章 2025-03-20
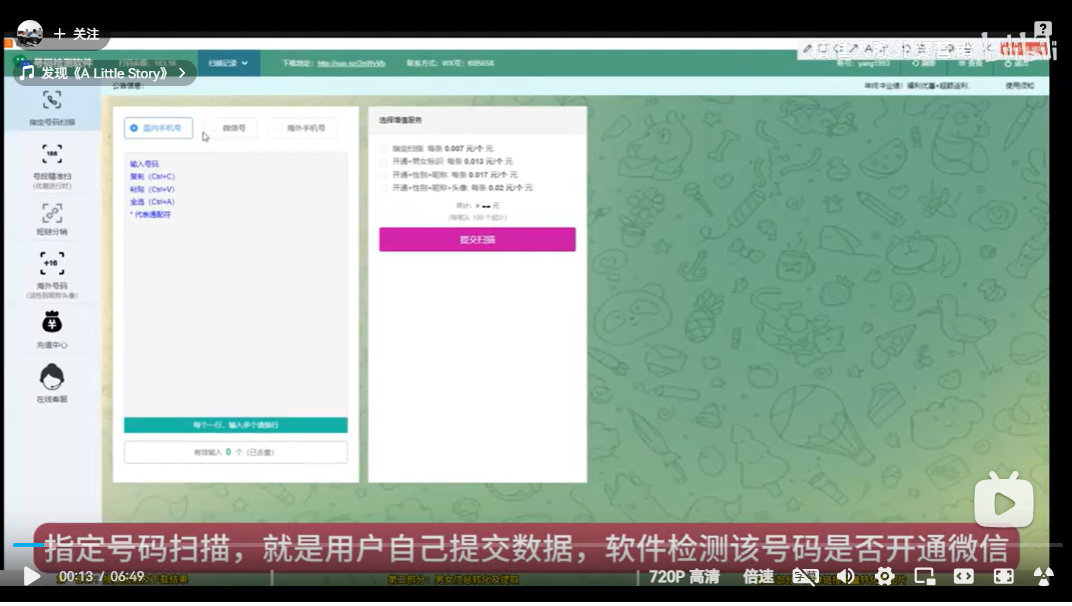
置顶 微信注册开通检测全功能版,可批量检测手机号码是否开通微信,国内号码筛选,港澳台号码筛选,国外号码,微信号QQ号等多种号码格式
-
发布了文章 2023-02-21
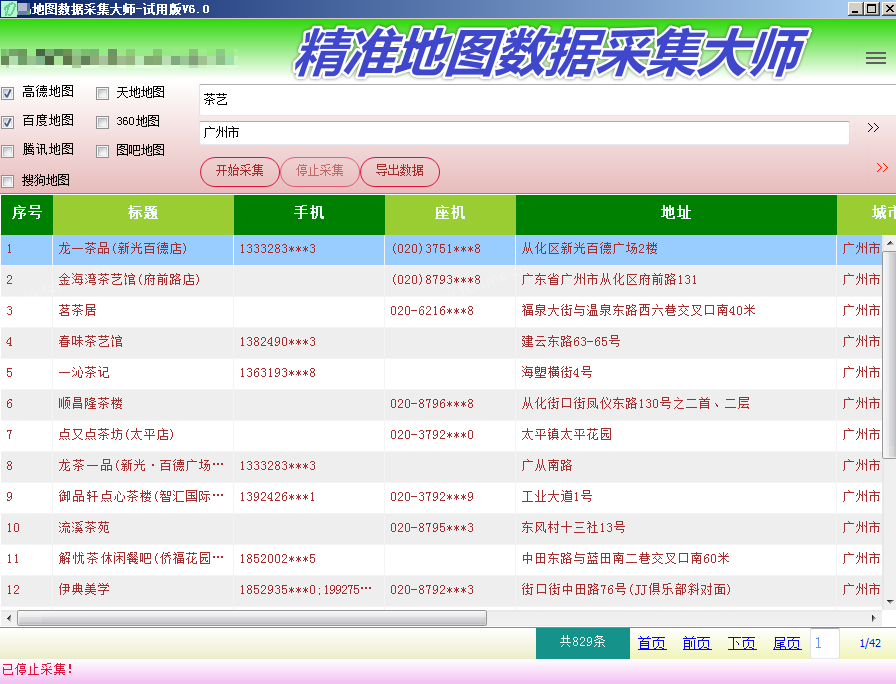
置顶精准地图数据采集大师详细介绍(电脑版,手机版)
精准地图数据采集大师详细介绍(电脑版,手机版)精准地图数据采集大师简介 精准地图数据采集大师安卓手机版是一款专业采集百度地图、360地图、高德地图、搜狗地图、腾讯地图、图吧...
-
发布了文章 2023-12-12
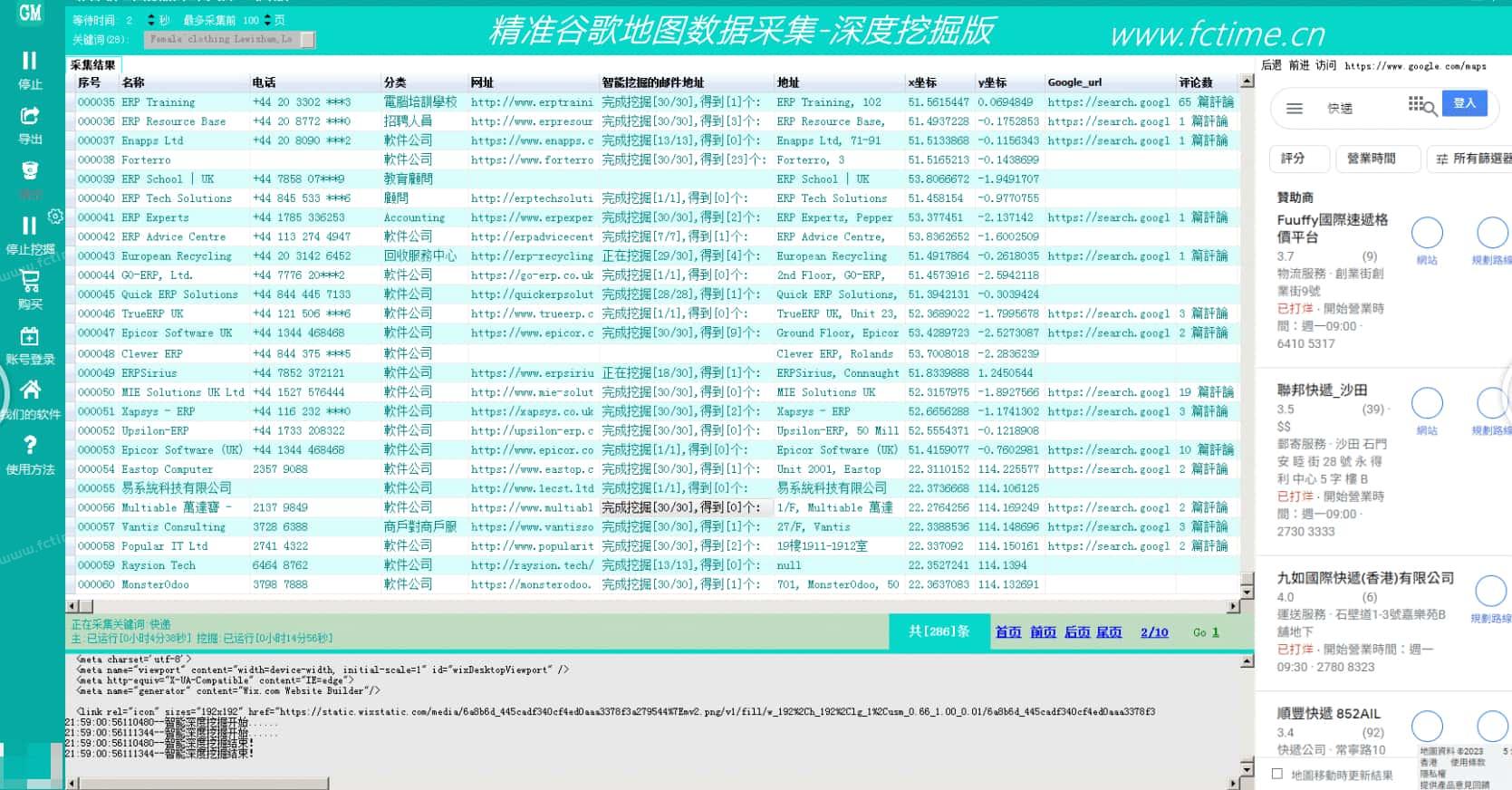
置顶精准谷歌地图外贸数据采集-深度挖掘(电脑版)
精准谷歌地图外贸数据采集-深度挖掘(电脑版)专为做外贸的朋友开发的一款基于谷歌地图数据采集的软件,可以采集任意国家、任意地区的公司地址、电话号码、邮件地址等数据。可以批量输入关键词采集、一键采集邮箱、一键导出、数据去重等,更...
-
发布了文章 2023-12-12
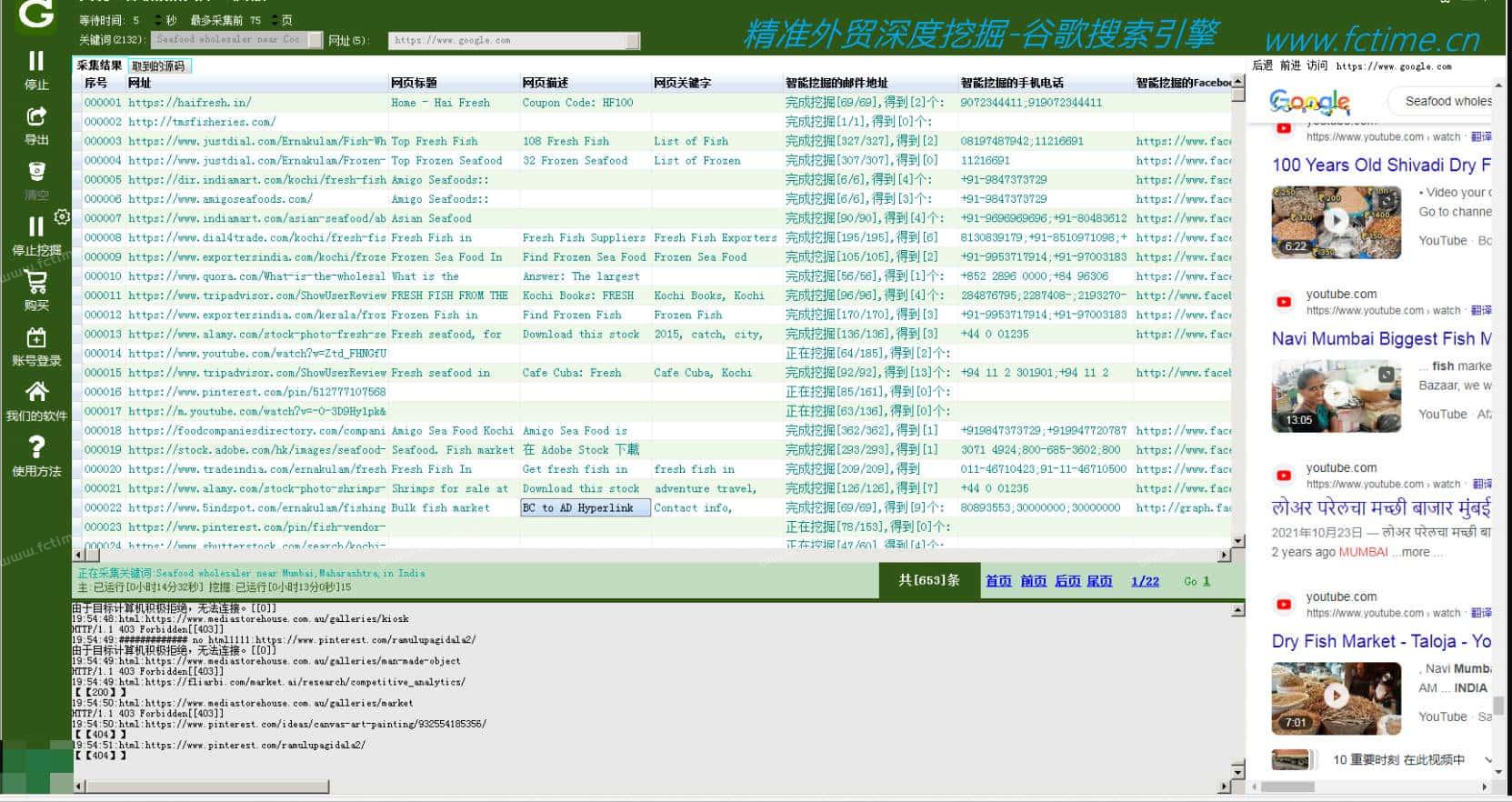
置顶精准谷歌搜索大师-外贸数据挖掘营销(电脑版)
外贸谷歌数据挖掘-精准谷歌搜索大师(电脑版)软件介绍谷歌搜索大师是一款以google搜索引擎作为基础进行智能数据挖掘的软件,采集的数据包括网站、标题、描述、邮件地址、手机或电话号码、facebook、linkin、twitt...
-
发布了文章 2024-03-03
置顶微信社群管理助手,微信社群去重,含社群引流、社群运营、社群裂变、积分营销、群发转发、自动回复、清理僵尸粉等等智能功能
微信社群管理助手,微信社群去重,邀请统计,社群管理机器人基于微信电脑客户端开发的群管辅助软件,为团队及企业提供智能营销及客户管理服务。会员说明1、不限群,不限微信号,同一台设备无限多开。2、另外,也有企微版必销客,企销客可以...
-
fctime.cn 2022-01-16
裂变微营销所有主题的互动
进行今日的微信,不但许多 用户沉浸于在其中,乃至很多企业早已入驻微信销售市场,互动交流已变成联接企业和用户的关键公路桥梁,在微营销下,怎样协助企业迅速与用户建立联系,这儿的互动交流能够协助企业保证这一点。 &nbs...
-
fctime.cn 2022-01-16
微商行业营销成功的秘诀
微商业服务营销成功的秘诀 1,渐近,轻描淡写一直是手机微信的盆友,要是沒有屏蔽掉你,在盆友圈中发消息,她们常常见到,因此 沒有必需担忧立刻让她们了解你的商品,恰当的方式是,第一次共享本人日常生活渗...
-
精准采集任意关键词、实时采集,激活码在哪?
精准采集任意关键词、实时采集,激活玛在哪?知识星球精华:2021-12-15 09:321.大家近期的营销难题 最近很多小伙伴都说业绩下滑,产品卖不出去,客户特别难找,订单不好找,线下生意真的很难做,销售人员也不容易招聘...
-

Pandownload时代结束了,会有其他软件替代它吗?比如现在的爬虫软件层出不穷?
4月16日上午消息,针对百度网盘“破解版”Pandownload 开发者被捕一事,百度网盘通过官方微博发布声明回应称,“积极配合警方,严厉打击侵犯百度网盘用户数据隐私的犯罪行为爬虫工具。”4月15日下午,@扬州网警巡查执法...
-
机器人软件、蜘蛛软件、爬虫软件、刷奖软件有什么区别?
机器人软件:使用机器代替人类操作,从而简化一些烦琐的人工操作,比如 12306购票软件,就属于机器人软件爬虫工具。蜘蛛软件(spider):蜘蛛,也就是搜索引擎爬虫工具。也就是模拟百度等搜索软件,爬取内容,然后抓取保存到本地...
-

Python什么爬虫库好用?
Python下的爬虫库,一般分为3类爬虫工具。抓取类urllib(Python3 ,这是Python自带的库,可以模拟浏览器的请求,获得Response用来解析,其中提供了丰富的请求手段,支持Cookies、Headers等...
-
好用的爬虫网站有哪些?
爬虫网站?是为了学习爬虫用来练手的网站,还是值爬虫工具爬虫工具。如果是前者的话,可以爬取豆瓣电影评论,也可以使用大牛的一个样例网站 / 去试试,还有各种网站都可以试试爬虫工具。如果是后者的话呢,可以使用精准 ,...
-

想学爬虫,具体要用到什么软件?如何操作?
这里有2种方法爬虫工具,一个是利用现有的爬虫软件,一个是利用编程语言,下面我简单介绍一下,主要内容如下:爬虫软件这个就很多了爬虫工具,对于稍微简单的一些规整静态网页来说,使用Excel就可以进行爬取,相对复杂的一些网页,可以...
-

有什么好用的股票交易数据爬虫类的软件?
这里以python为例爬虫工具,推荐一个免费、开源、跨平台的财经金融爬虫包—tushare,自动完成了数据从采集、清洗到加工的全过程,只需简单几行代码即可快速获取股票交易数据,操作简单、易学易懂,感兴趣的朋友可以尝试一下:下...
-
写爬虫用什么语言好?
爬虫选择什么工具呢爬虫工具?1.爬虫是网络蜘蛛机器人爬虫工具,自动爬取数据,按我们制定的规则获取数据2.为什么要用爬虫呢爬虫工具,私人定制搜索引擎,获得更多的数据,不再是互联网时代而是大数据时代3.爬虫的原理:控制节点(ur...
-

用什么样的爬虫工具可以抓取工厂电话?
人生苦短爬虫工具,我用Python! 论简便、易用性爬虫工具,个人强烈建议使用Python,其丰富强大的网络工具库、网页解析库,再加上Python简洁利落的语言特性,使得爬虫真的可以轻松无痛~ 一、网络请求:获取网页内容1、...
-

抓包工具有哪些,能抓什么?
谢邀爬虫工具。作为一名一线研发人员,下面介绍下工作中经常会用到的一些网络抓包工具,欢迎大家留言讨论。 1、WiresharkWireshark是一款流行的网络封包分析软件,功能强大爬虫工具。可以截取各种网络封包,显示网络封包...
-

爬虫软件究竟属不属于非法侵入、非法控制计算机信息系统程序、工具?
您好爬虫工具,看到您的问题,我作为同行,深表遗憾! 技术无罪,但您的行为确实是属于破坏信息系统安全措施和未授权非法获取数据,我前公司也就有一个同事,也是因为做爬虫,搜集他人网站信息被被别家公司告了,目前罚款并入狱爬虫工具。...
-

二手数据的采集方法?
1、第一:更重要的还是要先确认我们要收集的那个二手数据了,如果刚开始收集的过程中我们连这个数据都没有确认下来要收集什么样的,那么我们的工作就无法继续下去了数据收集。 2、第二:有一些数据,如果你收集的那个二手数据刚好是上市...
-
区块链将如何改变数据收集方式?
区块链技术及思想为21世纪供应链创新带来的启发有以下几点: 第一、解决孤岛问题数据收集,主要是“数据孤岛、信息孤岛、流程孤岛、资源孤岛、服务孤岛、信用孤岛、风控孤岛”,要解决这个孤岛问题,必须用去中心化、去核心企业化的理念重...
-

收集的数据怎样分类、整理?
信息时代,我们每天都会收集到非常多的各类数据,如果是专门从事数据收集和分析工作,数据量更会大的惊人,即便是从事其他工作,如何有效的收集、整理、查询和使用这些数据资源,来提高我们的工作效率呢?下面我来分享一些个人的经验数据收集...
-
HR如何做行业的业务调查、数据收集?
一般来说数据收集,对于行业数据收集的话,主要有以下几个方面: 行业一般都有行业组织数据收集,可以从行业组织获取,比如钢铁行业、汽车行业统计局统计数据,国家每隔一段时间会统计全国各地企业运行情况,便于做响应的政策调整,也可以从...
-
商业分析中,如何有效收集信息与数据,有哪些好的建议吗?
首先我们需要明白在商业活动中进行数据收集的目的是什么?如果我们只是应付管理层的工作安排,在繁忙的商业活动中抽点时间草草了事,那就失去了意义数据收集。我认为:商业活动中数据的收集首先是为了后期商业活动提供技术支持,其次是作为管...
