

微信检测可批量检测手机号码是否开通微信,国内号码,港澳台号码,国外号码,微信号QQ号等多种号码格式用户批量上传手机号码,平台将快速、自动、批量将手机号中有绑定或者开通微信的号码筛选出来,高速筛选、精准无痕,有效降低运营成本节...
网站首页 > fctime.cn 第23页
-
发布了文章 2025-03-20
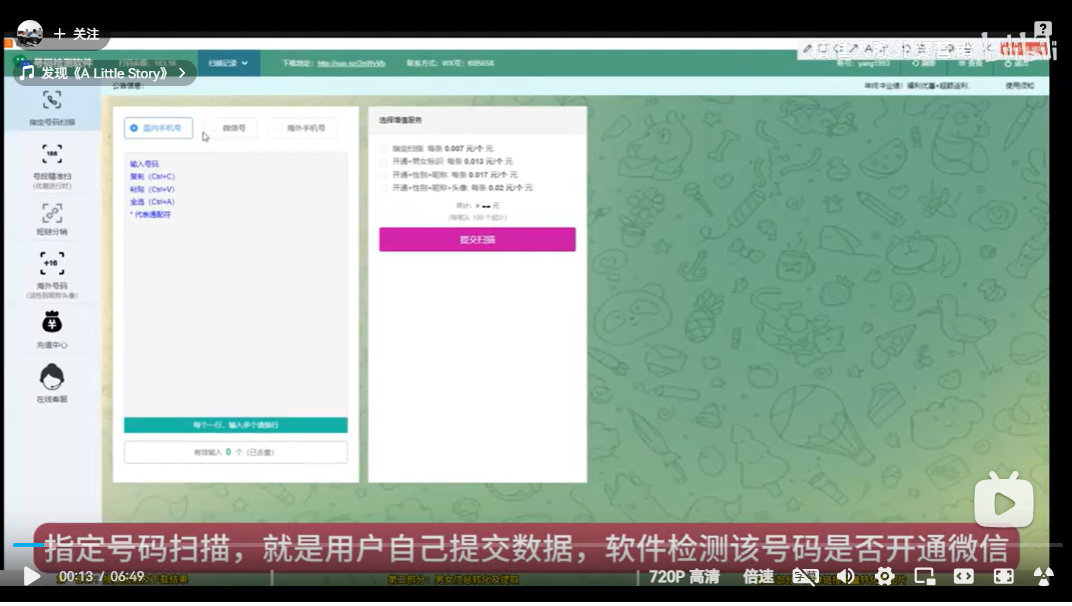
置顶 微信注册开通检测全功能版,可批量检测手机号码是否开通微信,国内号码筛选,港澳台号码筛选,国外号码,微信号QQ号等多种号码格式
-
发布了文章 2023-02-21
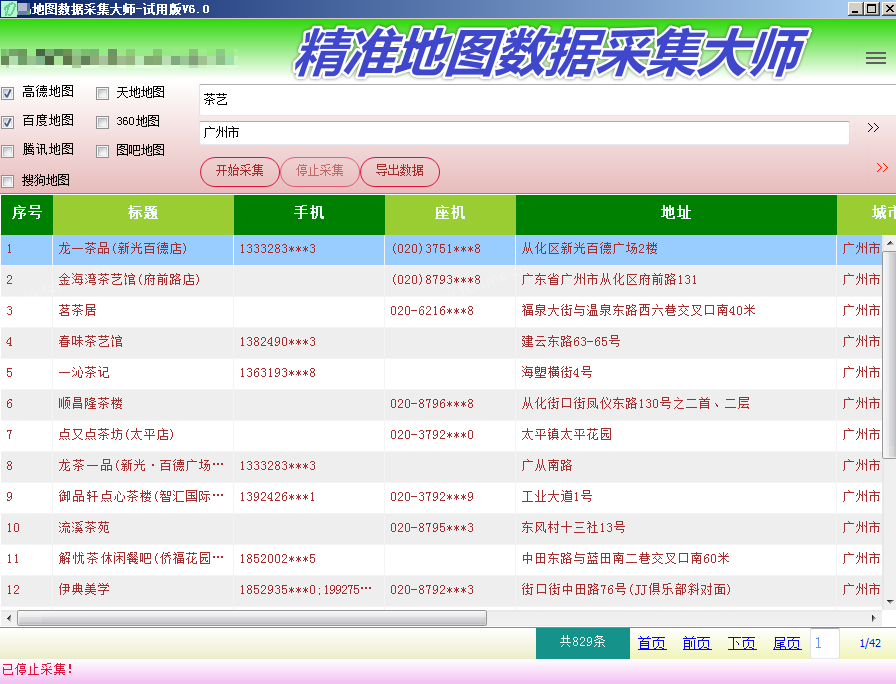
置顶精准地图数据采集大师详细介绍(电脑版,手机版)
精准地图数据采集大师详细介绍(电脑版,手机版)精准地图数据采集大师简介 精准地图数据采集大师安卓手机版是一款专业采集百度地图、360地图、高德地图、搜狗地图、腾讯地图、图吧...
-
发布了文章 2023-12-12
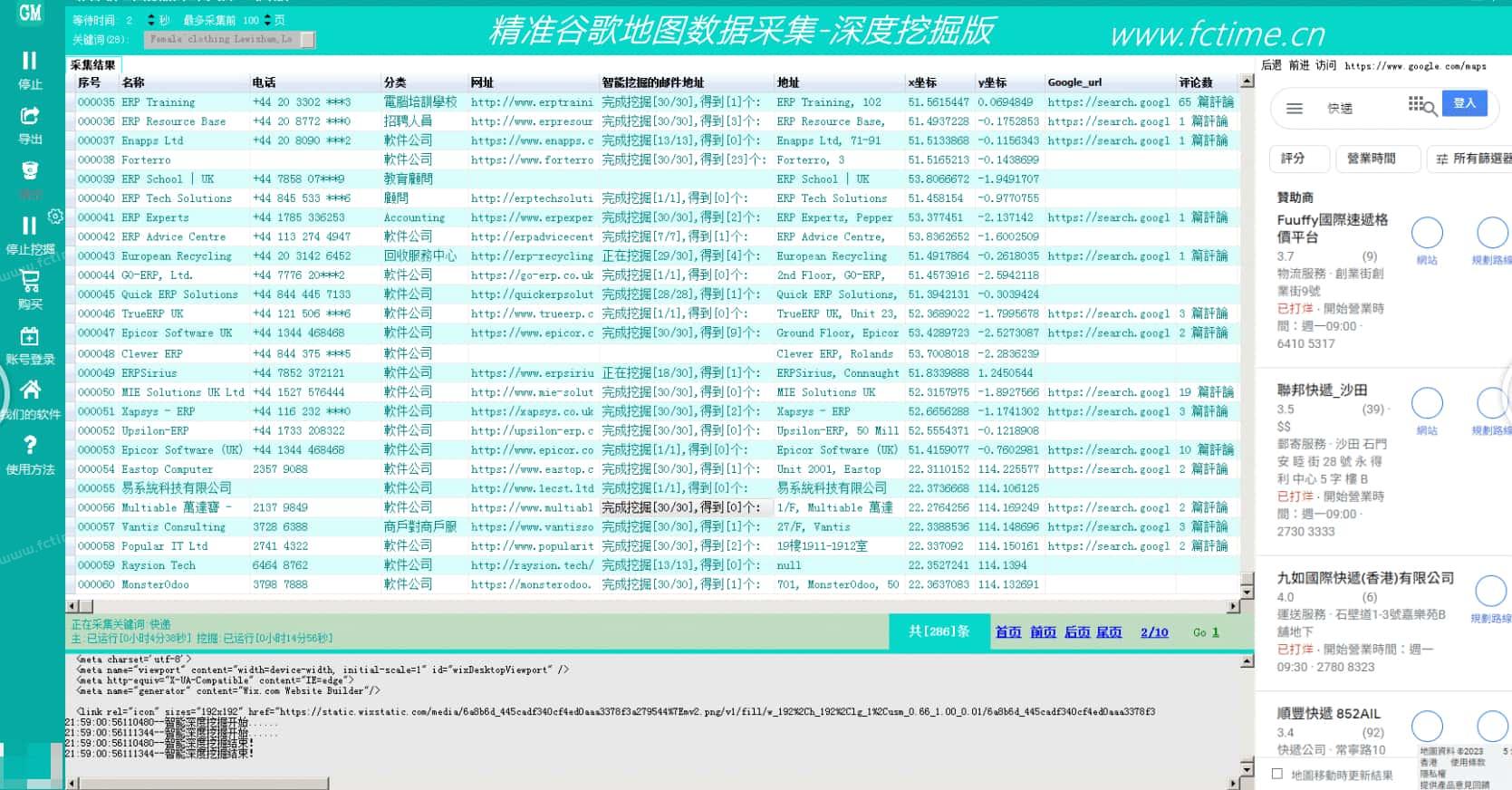
置顶精准谷歌地图外贸数据采集-深度挖掘(电脑版)
精准谷歌地图外贸数据采集-深度挖掘(电脑版)专为做外贸的朋友开发的一款基于谷歌地图数据采集的软件,可以采集任意国家、任意地区的公司地址、电话号码、邮件地址等数据。可以批量输入关键词采集、一键采集邮箱、一键导出、数据去重等,更...
-
发布了文章 2023-12-12
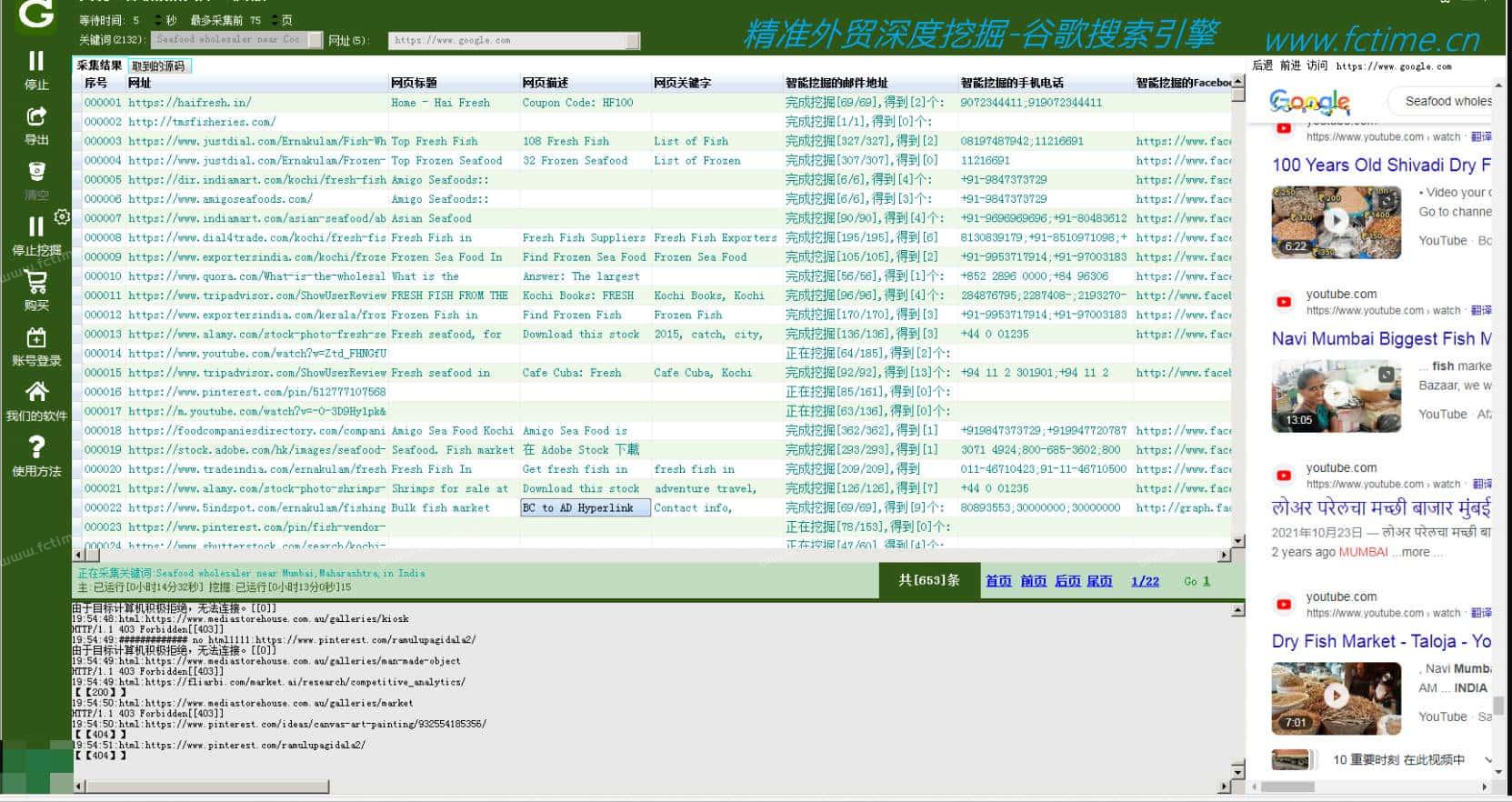
置顶精准谷歌搜索大师-外贸数据挖掘营销(电脑版)
外贸谷歌数据挖掘-精准谷歌搜索大师(电脑版)软件介绍谷歌搜索大师是一款以google搜索引擎作为基础进行智能数据挖掘的软件,采集的数据包括网站、标题、描述、邮件地址、手机或电话号码、facebook、linkin、twitt...
-
发布了文章 2024-03-03
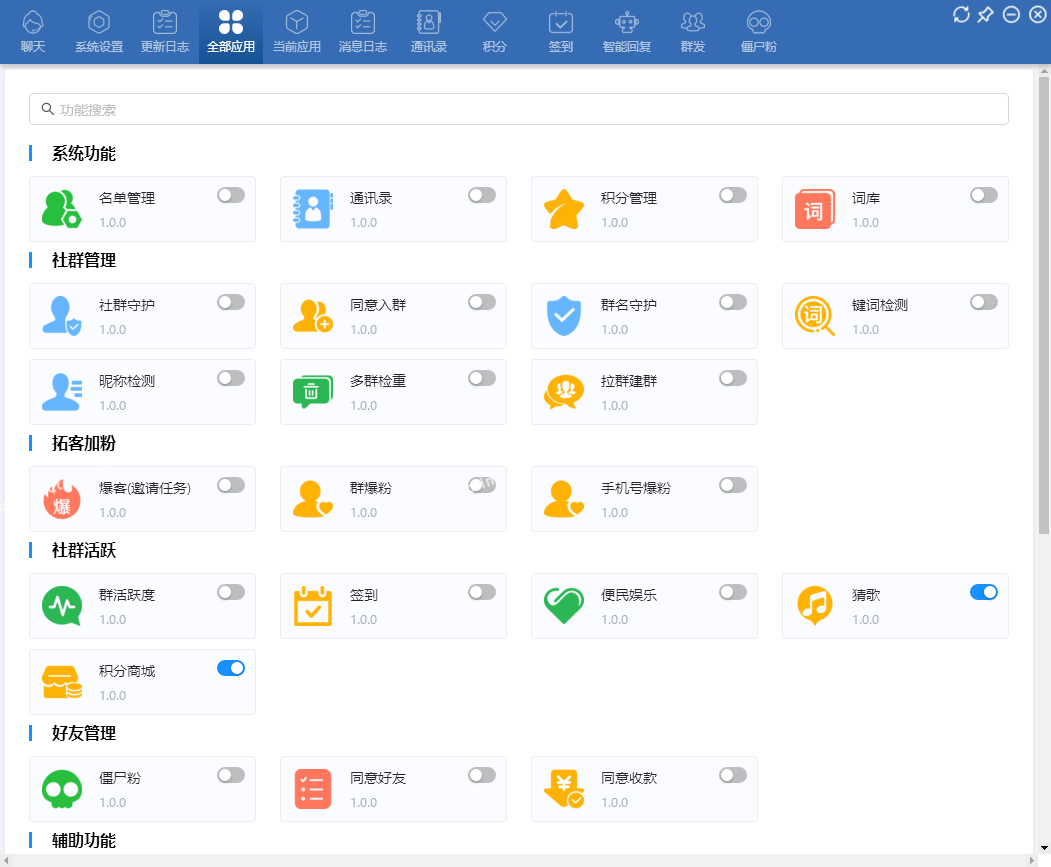
置顶微信社群管理助手,微信社群去重,含社群引流、社群运营、社群裂变、积分营销、群发转发、自动回复、清理僵尸粉等等智能功能
微信社群管理助手,微信社群去重,邀请统计,社群管理机器人基于微信电脑客户端开发的群管辅助软件,为团队及企业提供智能营销及客户管理服务。会员说明1、不限群,不限微信号,同一台设备无限多开。2、另外,也有企微版必销客,企销客可以...
-

数据收集引发隐私争议,微软如何向Office用户提供更多控制权?
近年来,微软对自家产品和服务引入了更加激进的数据收集政策,但这也惹恼了许多注重隐私的客户数据收集。 无论是 Windows 10 操作系统,还是 Microsoft Office 生产力套件,均包含了获取遥测数据的功能数据收...
-
在我们生活中,都可以用那些方法收集和整理数据呢?
观察、参观、查阅资料数据收集。 对于数据的收集数据收集,往往需要做大量的工作其一般过程为 明确调查的目的,确定调查对象数据收集。 选择合适的的调查方式数据收集。 展开调查活动,收集数据数据收集。 数据的整...
-

数据的收集、整理、分析的步骤和方法是什么?
做过孩子数据分析的启蒙课,我来回答数据收集。 1.从绘本开始幼儿园大班孩子数据收集,有一天给他讲课一个绘本《王牌小汽车》,大致的意思是: 有一辆小汽车想在“王牌汽车大会”赢得第一名数据收集。他开始想办法:首先他去咨询每辆车...
-

如何收集绩效原始数据?
绩效原始数据一定要来源于内部经营管理报表对于绩效管理,一定要强调数据,无数据、不考核数据收集。数据说话是做绩效管理必须遵循的一个基本准则,因为数据是死的 ,数据是不会骗人的,通过数据能很客观地评价出价值结果。 那么到底该如何...
-

收集数据通常可以采用的方法有哪三种?
1.访谈调查:访谈调查,也称为派遣调查,是调查者和被调查者面对面交谈以获取所需信息的一种调查方法数据收集。 2.邮寄调查:邮寄调查是一种调查方法,通过邮件或其他方式将问卷发送给被调查者,由被调查者填写,然后寄回或送到指定的收...
-

手机号码获取,网站获取手机号码,APP获取手机号
**手机号码获取号码采集器,网站获取手机号码,APP获取手机号** 公众号:大海啊好多水 怎么样才能获取到用户的手机号码呢号码采集器? 1、调查问卷填写手机号码 做运营,不管是大平台还是小平台,都会定期发布用户调查问卷,了...
-

以案释法|突然收到验证码?可能“嗅探”在盗刷你的银行卡!
手机和银行卡都在身上 账号和密码也没有外泄 但一觉醒来 银行账户和支付宝的钱却被“掏空”了 2017年上半年 金某、李某等人 利用嗅探等设备 隔空刷走了多人账户存款 案情简介 2017年7月底开始,石狮警方陆续接到多...
-
不会rap,也要学会猜韵脚 (小程序支持一键获取手机号啦)
我的爱好和蔡徐坤居然一样:“唱、跳、rap、和篮球” 虽然我不会rap,只会一首蹩脚的“hello everyboy ,在你头上暴扣”号码采集器,但也沉浸其中: 而在freestyle环节中号码采集器,选手之间的过招更加彰显...
-

电话号码采集的方法
电话号码是各行各业找客户的敲门砖号码采集器,虽然有很多地方可以找到电话资源,但对很多企业来说仍然是一个难题,那么电话号码采集有哪些方法呢? 前言各行各业找客户,其实就是在找联系人的电话号码,电话号码可谓是敲门砖,无论敲门成...
-

关于号码采集盒子之工作原理介绍
如果你是做的方圆2公里内的生意,服务人群客户主要在5公里范围内,你有没有想过如何获取到你生意覆盖范围内人群的手机号码呢,对自己的服务和产品进行主动的营销号码采集器。 这款设备就是专门为获取周边人群号码而生号码采集器。直线...
-

“探针盒子”被曝光后仍在售 可盗取周边用户手机号
探针盒子“盗号” 被曝光后仍在售 能获取联网用户电话信息 平台方称将审核涉事商品 律师认为涉嫌侵犯他人隐私 今年央视3·15晚会曝光了一种WiFi探针盒子,这种盒子能在用户毫不知情的情况下,获取用户手机MAC地址,并将其转换...
-

自媒体爆文采集器有吗?
很荣幸回答你的问题号码采集器。 我知道的阅读爆文的平台有三个号码采集器。 1.新榜 通过这个网站,可以知道每天,每周,每月更受欢迎的公众号,头条号和文章都是什么号码采集器。 有排名有阅读量号码采集器。 2.淘金阁 这个是...
-
请问做自媒体和媒体号的运营喵们都用什么工具呢?
目前做自媒体号码采集器。主要用到的工具我可以从我自己做自媒体这一块给大家分享一下。首先我们做好自媒体,我们需要一些基本的辅助工具。比如说文章采集工具。原文检测工具。以及文章的排版工具。假如我们是做视频的我们还需要一些视频的剪...
-

有什么好用的公众号数据监测工具?
西瓜数据 用手机端怎么查询公众号数据并且进行监测在西瓜数据 这些功能分别解决你以下问题 历史广告推文:可以快速了解公众号都接过什么类型的广告,如果公众号有发文字链也会显示在内号码采集器。 数据统计:可以快速查看公众号头条、次...
-
附近人手机号码采集
附近范围人群手机号码采集软件设备包含一个硬件盒子和软件app,它可以采集到附近范围500米到2公里内陌生人群正常开机的手机号码,对于采集获取来的附近人手机号码,利用营销工具可以拨打电话,发送短信号码采集器。 我们可以称它为附...
-
现在哪些采集工具,可以采集我做科研的临床数据吗?就是医院里面的软件数据?
现在的采集工具很多,看你们科研数据是结构化数据还是非结构化数据采集工具。结构化就是关系型数据库中的数据,如:mysql,Oracle,Sql server等数据库中的数据。非结构化数据比如你们医疗系统每天运行的日志,每件精密...
-

视频采集工具好用吗?
易撰视频采集工具挺好用的,由于自媒体行业的发展,很多人不是只在一个平台上进行视频的发布,而是在很多平台上同步进行分发,获得更多的流量,也能帮助自己更好的树立品牌效应,大家可以用蚁小二进行视频的免费一键分发,一键分发30多个平...
-

什么样的社区才能叫做智慧社区?
产业链介绍一、智慧社区行业产业链简介在新的市场环境下数据采集终端,智慧社区已经从单纯的设备制造商、系统集成商主导,变为各方参与,互利共赢的局面,产业链上下游涉及房产开发商、物业/社区运营商、业务提供商、设备提供商、系统集成商...
