

微信社群管理助手,微信社群去重,邀请统计,社群管理机器人基于微信电脑客户端开发的群管辅助软件,为团队及企业提供智能营销及客户管理服务。会员说明1、不限群,不限微信号,同一台设备无限多开。2、另外,也有企微版必销客,企销客可以...
-
发布了文章 2024-03-03
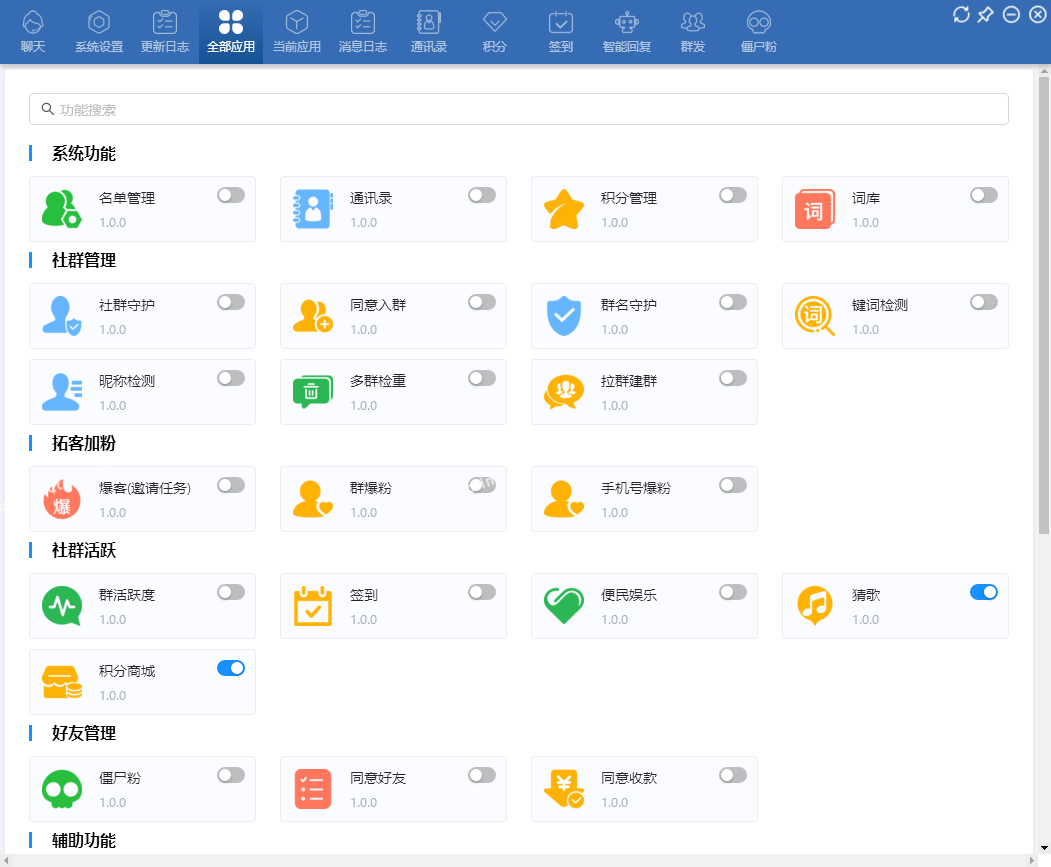
置顶微信社群管理助手,微信社群去重,含社群引流、社群运营、社群裂变、积分营销、群发转发、自动回复、清理僵尸粉等等智能功能
-
发布了文章 2023-12-12
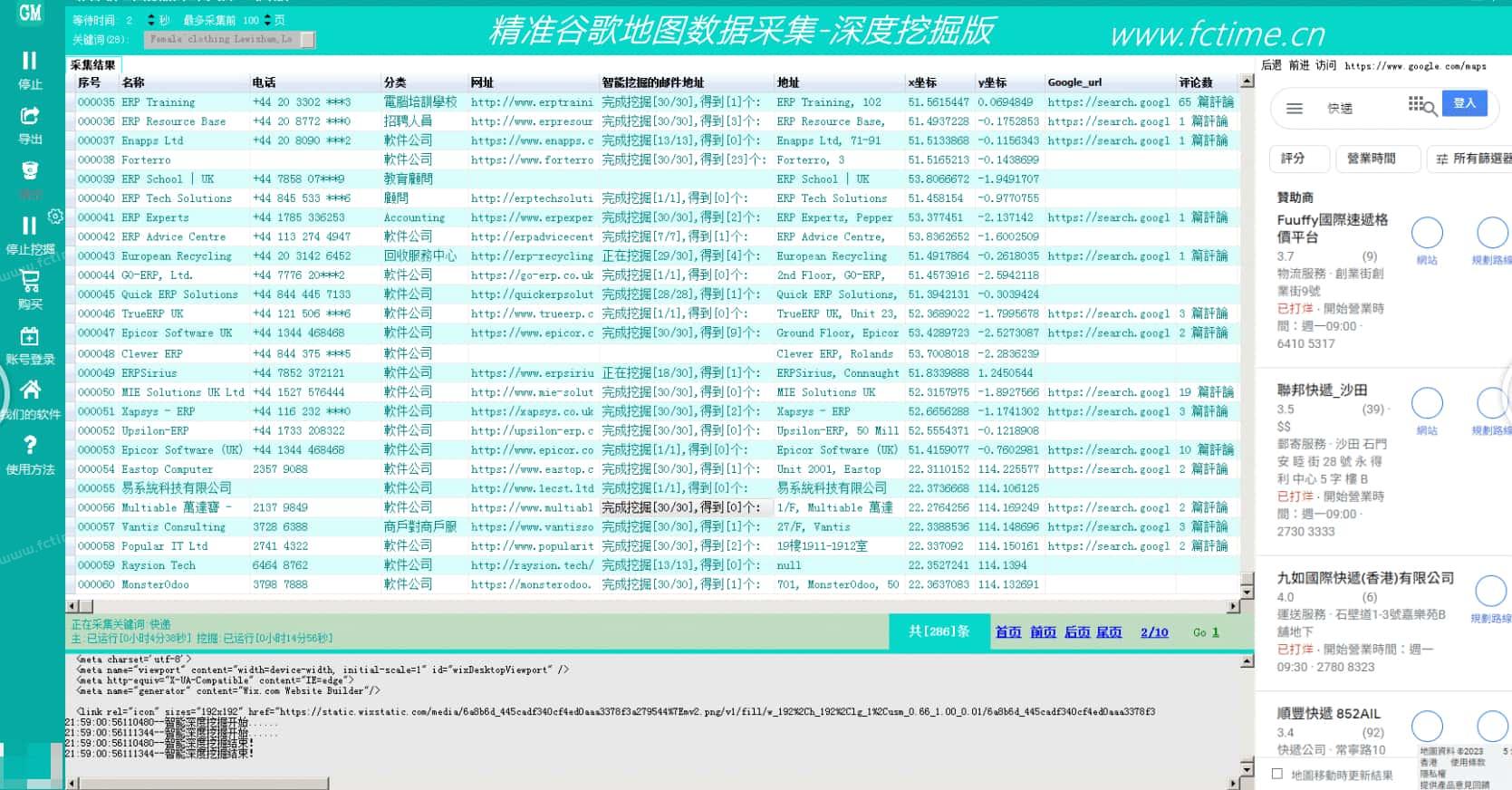
置顶精准谷歌地图外贸数据采集-深度挖掘(电脑版)
精准谷歌地图外贸数据采集-深度挖掘(电脑版)专为做外贸的朋友开发的一款基于谷歌地图数据采集的软件,可以采集任意国家、任意地区的公司地址、电话号码、邮件地址等数据。可以批量输入关键词采集、一键采集邮箱、一键导出、数据去重等,更...
-
发布了文章 2023-02-21
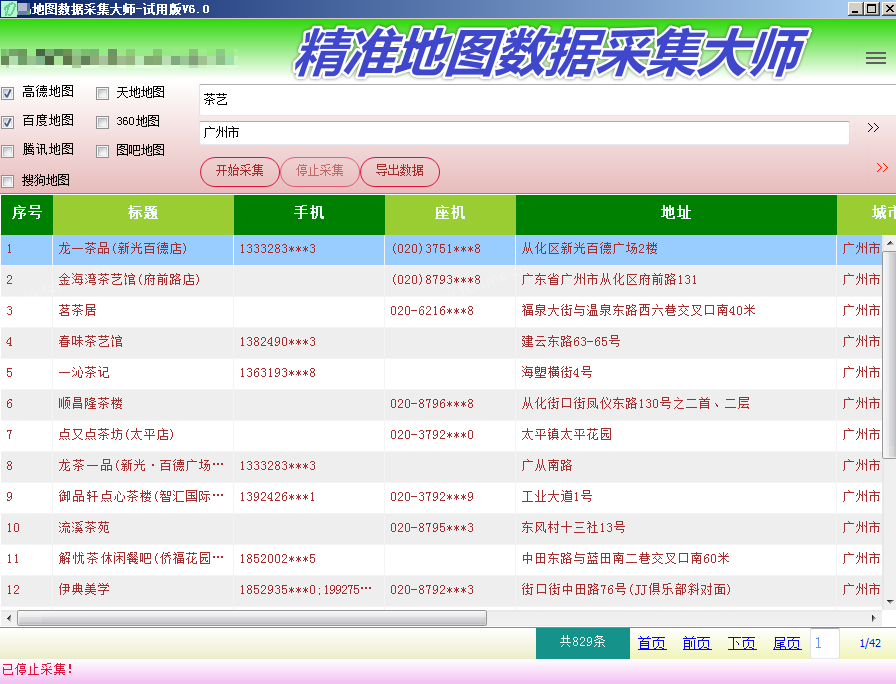
置顶精准地图数据采集大师详细介绍(电脑版,手机版)
精准地图数据采集大师详细介绍(电脑版,手机版)精准地图数据采集大师简介 精准地图数据采集大师安卓手机版是一款专业采集百度地图、360地图、高德地图、搜狗地图、腾讯地图、图吧...
-
发布了文章 2023-12-12
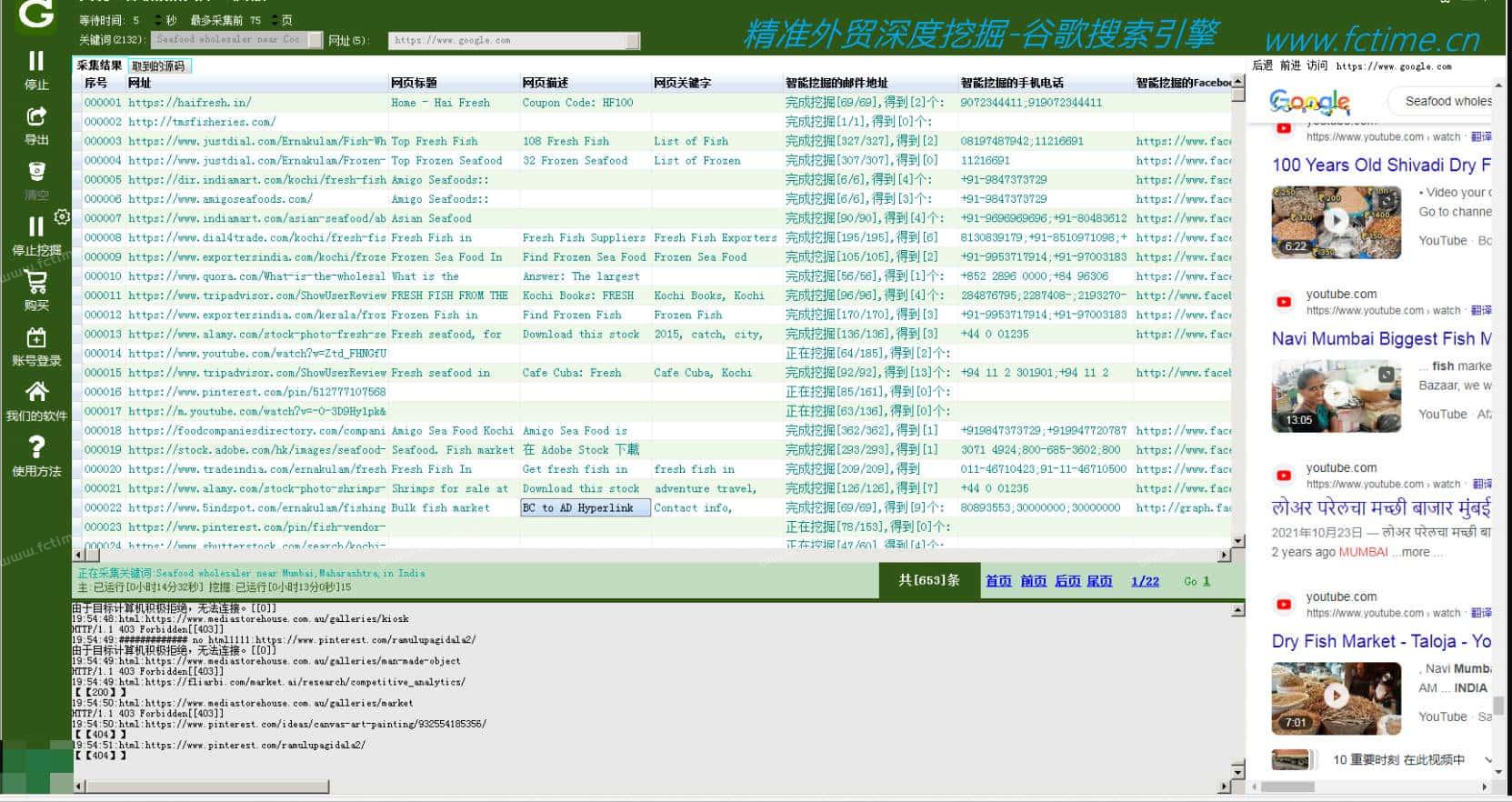
置顶精准谷歌搜索大师-外贸数据挖掘营销(电脑版)
外贸谷歌数据挖掘-精准谷歌搜索大师(电脑版)软件介绍谷歌搜索大师是一款以google搜索引擎作为基础进行智能数据挖掘的软件,采集的数据包括网站、标题、描述、邮件地址、手机或电话号码、facebook、linkin、twitt...
-
发布了文章 2025-03-20
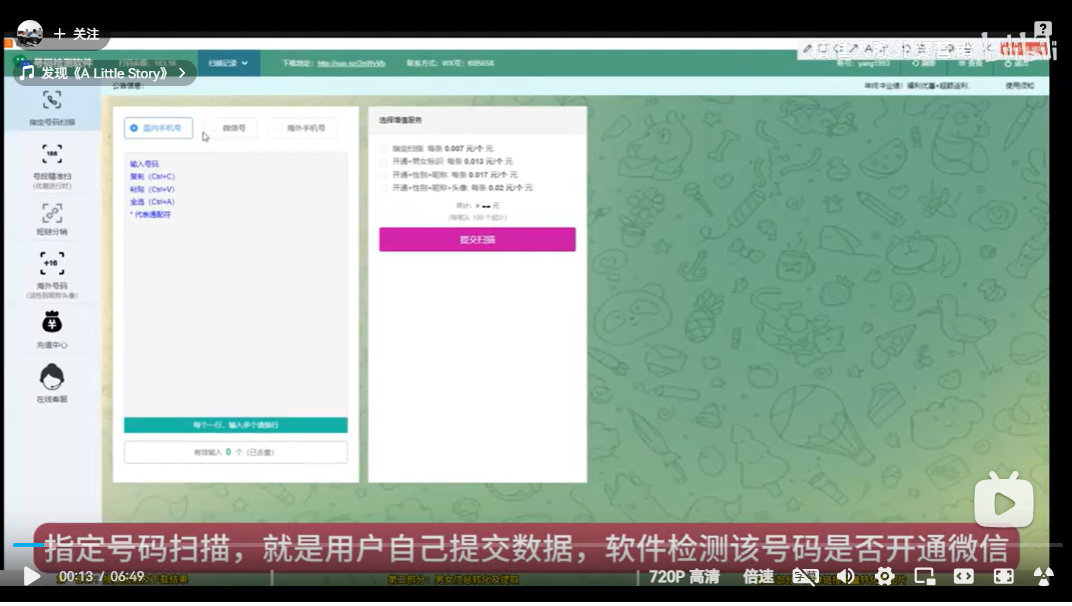
置顶 微信注册开通检测全功能版,可批量检测手机号码是否开通微信,国内号码筛选,港澳台号码筛选,国外号码,微信号QQ号等多种号码格式
微信检测可批量检测手机号码是否开通微信,国内号码,港澳台号码,国外号码,微信号QQ号等多种号码格式用户批量上传手机号码,平台将快速、自动、批量将手机号中有绑定或者开通微信的号码筛选出来,高速筛选、精准无痕,有效降低运营成本节...
-
发布了文章 2025-06-14
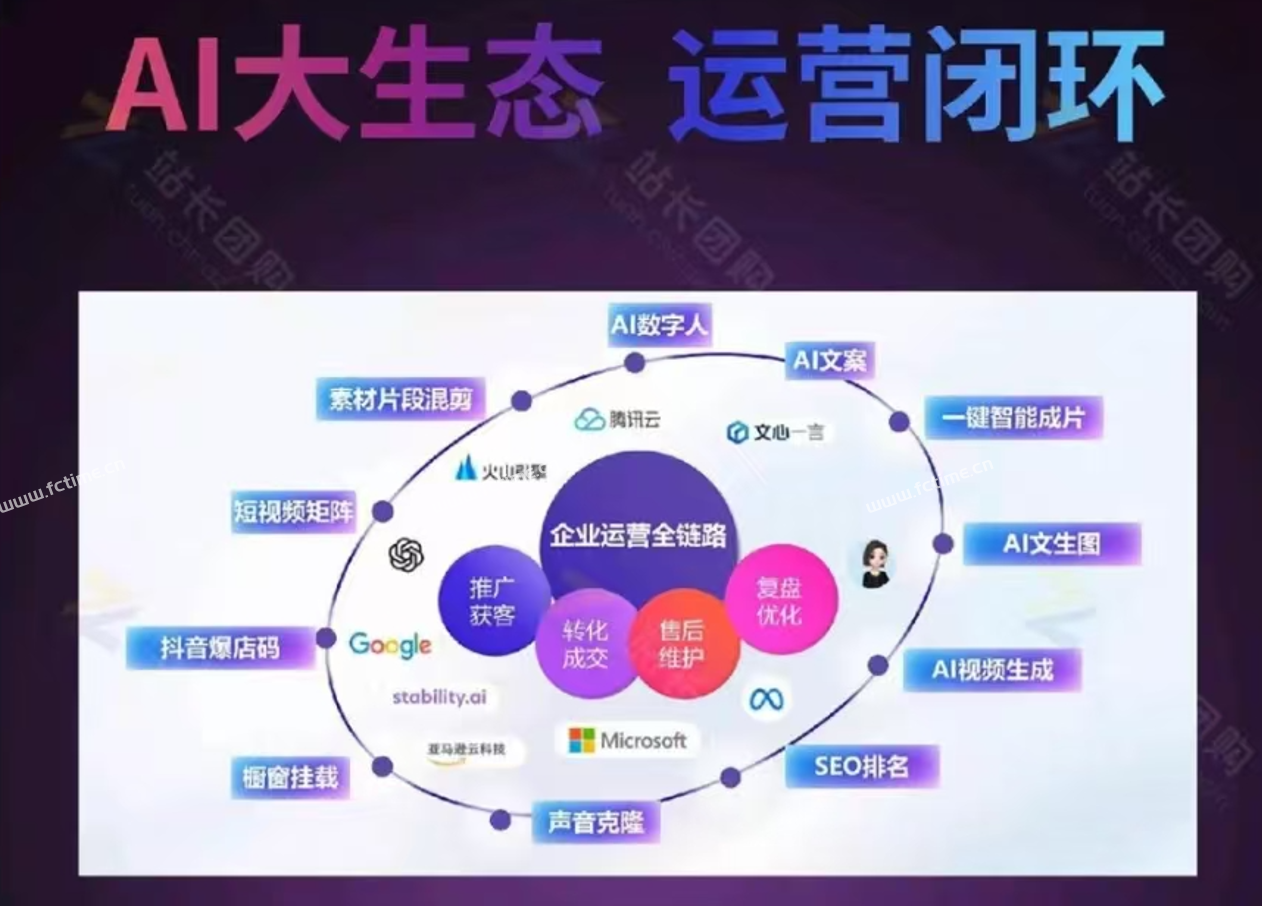
置顶企业短视频矩阵运营助手详细图文介绍,AI数字人,AI文案,AI视频
企业短视频矩阵运营助手详细图文介绍算力消耗:以积分形式消耗系统成本折算成积分,1元100积分以数字人克隆为例短视频矩阵整体功能截图手机版截图电脑端后台截图数据大屏矩阵授权短视频矩阵,任务管理图文矩阵管理UGC裂变码多模式视频...
-

抓取网页数据,任何网站都能抓取的工具有吗?
抓取上传过程:鼠标右键选择【抓取商品】工具网站信息采集器,并选择需要抓取的平台,如图第1步:选择抓取商品的使用方式有3种抓取商品方式网站信息采集器,在这里以B方式做详细介绍,其他方式请查看相关文字提示输入要抓取的宝贝地址或店...
-

请问,有采集飞猪网数据的工具推荐吗?
现在许多软件可以实现网站信息采集器,不需要编程,如精准 、精准 采集器、gooseeker等,需要登录的系统,从浏览器登录信息中获取cookie,然后配置到软件中就能实现模拟登录,后续需要提取网页数据,一般通过xpath...
-

有没有什么工具能帮我爬实验数据?
可以试着用一下精准 爬取数据!全名叫做精准 数据采集器,事深圳的一家公司开发的网站信息采集器。使用简单功能强大!爬取范围很广泛金融数据,如季报,年报,财务报告, 包括每日更新净值自动采集; 各大新闻门户网站实时监控,自动...
-

有没有网站数据抓取的软件?
也算是入乡随俗,如果是不在乎具体某个网站,单分析某个词出现的频率,大概率要提到百度指数,毕竟百度目前在中文互联网搜索引擎市场份额更大,百度指数又是基于海量网民搜索行为数据加以分析,因此目前也是企业经营决策的重要依据网站信息采...
-

99%网站站长都不知道,居然有免费万能采集器
SEOer大家好,小编今天要讲一些对大家非常有帮助的知识点网站信息采集器。网站内容应该怎么采集,怎么使用采集工具进行采集,长期是采集会出现的状况,以及如何处理这些问题。采集工具的话,采集的内容网站信息采集器。第一,它采集的内...
-

如何采集网页数据?复制粘贴吗?
如何采集网页数据?你说复制粘贴网站信息采集器,这就纯属抬杠了?网页数据主要来自网络接口和静态文件网站信息采集器,要采集这些数据,主要还是通过解析文件和接口数据获取,不同网站的接口约定和页面结构都是不同的,如果要自己采集很多网...
-

高效获取资源的4种方式,城外采集更靠谱,值得推荐
各位万国的小伙伴们大家好,众所周知,《万国觉醒》是一款策略型手游,开局就给点资源和农民,然后玩家就可以靠着这点资源慢慢发展,一直做到可以“称霸世界”资源采集。但是在这个过程中,我们不仅要有超凡的智慧,还得有大量的资源进行支撑...
-

这么多做自媒体,资源在哪里来呢?
很多自媒体人做着做着就不知道应该创作什么内容了,怎么办?不做了,放弃了,看着自己好不容易起来的粉丝,不忍心啊,就这么放弃了心有不甘资源采集。但是总不能随便创作吧?那粉丝更不愿意看了,怎么办?凉拌,只能去再次找更多的资源了,但...
-

自媒体新手用哪些平台自媒体信息采集软件或网站更好?
其实视频采集软件还真有网站信息采集器,并且不只是一个,是三个,下面不吊大家胃口,直接上干货!1.自媒咖进入之后看哪个视频想采集,直接点击视频,进入下载页面,然后点击下载就可以了网站信息采集器。主要包含百度好看,西瓜视频,美拍...
-

想做自媒体,各位大神都是从什么渠道获取资源的?
做自媒体获取资源的渠道应该有很多,我是从我们从事的行业寻找资源,我们是一家做婚礼策划,婚纱摄影的公司资源采集。我准备在自媒体上给大家分享一些婚俗方面的内容,寻找一些与众不同的爱情分享。给大家讲解一下各种各样的婚礼主题。给大家...
-

自媒体,哪里去找素材资源?
这应该是三个问题资源采集,根据个人经验,我会分开来回答:曾经和小伙伴一起创业,做的就是资源整理的站点,当然这是已经很久之前的事了,所以如何发掘内容,查找资源还是有一些心得的资源采集。自媒体素材资源哪里找:1 那些专业媒体漂亮...
-

在海盗游戏《ATLAS》中更强的资源采集神兽是哪个?
在各大沙盒游戏中资源采集,采集资源都是很常见的一件事,因为你要建造自己的家园的材料总不能是凭空而来的吧,必须要通过自己的双手去采集,只不过这个过程一直都是在做一件事,让玩家感到很不耐烦,为了减轻玩家的焦虑,在Steam上发布...
-

方舟生存进化手游,如何自动采集资源?
一、杀三叶虫、龙王鲸、水蛭尸体都可以获得少量石油,或者驯养几只粪甲虫,分解粪甲虫的粪便也可以得到化肥跟石油资源采集。二、雪山开采,石油通常会在方舟世界的雪原地图出现,像这种黑黑的竖型石头就是石油了,用镐子或甲龙就可以采集了,...
-

做影视盘点,混剪的,请问下怎样快速找素材?
影视领域的创作者资源采集,更重要的就是找素材,剪辑吧!我就分享一下自己做影视领域这块的心得吧资源采集。首先呢,我没有说是耗费大量时间去找素材的,都是自己一边看剧,一边把自己当下看到的觉得大家感兴趣,或者是我个人觉得挺有意思的...
-

人力资源的详细流程?
人力资源部工作流程 ◇人力资源规划流程: 一、 调查、收集和整理涉及企业战略决策和经营环境的各种信息资源采集。 二、 根据企业或部门实际情况确定其人力资源规划期限资源采集。 三、 在分析HR需求和供给的影响因素的...
-

烟雨江湖傀儡怎么采集资源?
1、获得傀儡后前往资源点,接着点击【包袱】资源采集。2、之后选中傀儡后接着再点击【放置】功能资源采集。3、这样就在资源点上放置傀儡了,之后傀儡就会开始工作了资源采集。4、当傀儡采集到资源后,接着再点击游戏页面中的【地图】资源...
-

桌面软件数据采集有什么好方法吗?
一、软件接口方式各个软件厂商提供数据接口,实现数据采集汇聚数据采集软件。二、开放数据库方式实现数据的采集汇聚,开放数据库是最直接的一种方式数据采集软件。两个系统分别有各自的数据库,同类型的数据库之间是比较方便的:1. 如果两...
-

有没有高效又傻瓜一点的爬虫采集数据工具?
当然是有的数据采集软件,下面我简单介绍3个非常不错的爬虫数据采集工具,分别是精准 、精准 和精准 ,对于大部分网络(网页)数据来说,这3个软件都可以轻松采集,而且不需要编写一行代码,感兴趣的朋友可以尝试一下:精准 采...
-
有什么好用的免费电商爬虫软件?
这里介绍2个非常不错的爬虫软件数据采集软件,分别是精准 采集器和精准 采集器,对于网络上大部分数据来说,这2个软件都能轻松爬取,而且不需要编写任何代码,下面我简单介绍一下这2个软件的安装和使用,感兴趣的朋友可以自己尝试一...
-

能够导出网页上的数据,还能导出系统软件上的数据,网上有我需要的数据导出工具吗?怎么样?
导出网页上的数据数据采集软件,说的明白一些就是网络爬虫,基于一定规则或手段自动抓取特定网页的数据,然后转储为excel等文件,至于工具的话那就非常多了,许多采集器都可以轻松实现,下面我简单介绍3个,感兴趣的朋友可以尝试一下:...
-

爬虫软件都有什么,想从网上爬一些数据,必须写代码吗?
这个不一定数据采集软件,爬虫只是一个数据获取的过程,不一定非得会代码,目前网上有许多现成的软件都可以直接爬取数据,下面我简单介绍3个,分别是精准 、精准 和精准 ,感兴趣的朋友可以尝试一下:01简单软件—精准 采集器...
-

AI智能呼叫变“AI骚扰”?借电话采集声音更需警惕
“您好,我是您的手游顾问,XX游戏邀请您进行公测……”“您家净水器滤芯该换了,还有机会参加双11优惠哦……”记者近日发现,消费者频繁接到的营销电话很多已经不是来自真人,而是智能呼叫系统在操作电话号码采集。公众深恶痛绝的骚扰电...
